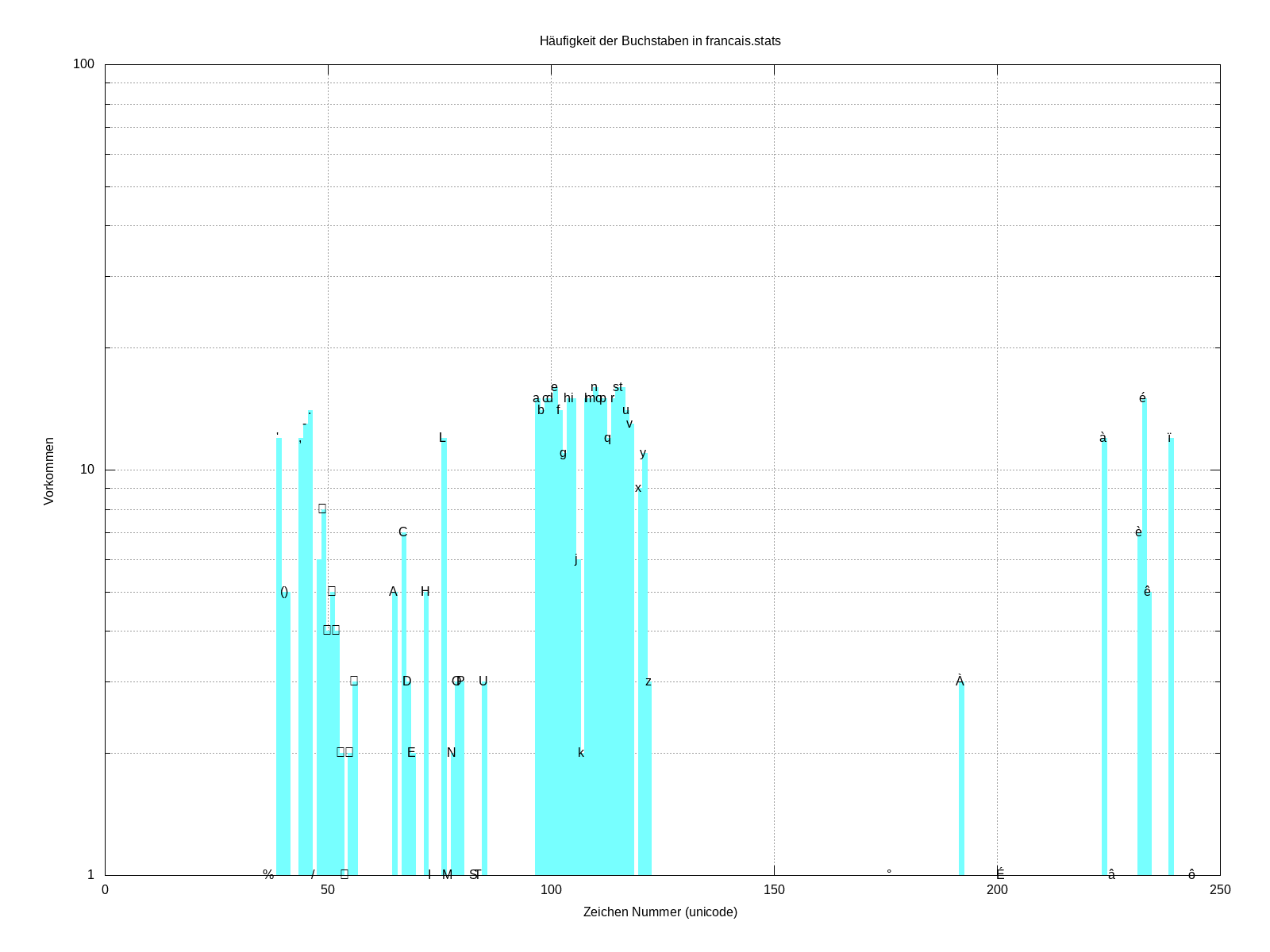
Zeichen-Histogramm von Texten
Die Häufigkeitsverteilung von Zeichen in Texten ist in mancher Hinsicht interessant, z.B. in der Kryptografie bei der Entschlüsselung von Substitutionschiffren. Diese Verteilung kann man mit Gnuplot analysieren und auch grafisch darstellen:
 gnuplot Skript Download
gnuplot Skript Download#!/usr/bin/gnuplot
#load includefile
# Definiere die Breite der Bins (“bin width”, ∆x)
# und eine sog. “binning”-Funktion:
# Die Funktion ceil(x) rundet den Wert von x ab
# Die Anzahl der Datenpunkte (für die Normierung)
set terminal png size 1600,1200
set output PNG
#set decimalsign locale "de_DE.UTF-8"
set size 0.95,0.95
set origin 0.03,0.03
set grid #linestyle 30, linestyle 31
set grid xtics mxtics ytics mytics
set title sprintf("Häufigkeit der Buchstaben in %s", datei1)
set logscale y
set xlabel "Zeichen Nummer (unicode)"
set ylabel "Vorkommen"
set mytics
set boxwidth 1 absolute
set style fill solid 1
plot datei1 \
using 1:4 with boxes lc rgb "0x1177ffff" notitle, \
'' using 1:4:(sprintf("%c",$3)) with labels notitle
#!/bin/bash
#
# Erzeugt eine Häufigkeitsanalyse für einen UTF-8 Kodierten Text
IN=$1
AUS=$IN.stats
echo "Buchstabenhistogramm der Datei $IN" > $AUS
for ((n=32; n<2100; n++))
do
Nhex=$(printf "%04x" $n)
Ndez=$(printf "%04i" $n)
Nu=\\x{$Nhex}
x=$(grep -c --perl-regexp ${Nu} "$IN")
if [ "$x" != "0" ]
then
echo -e "$Ndez $Nu \u$Nhex $x " >>$AUS
fi
done
gnuplot -e "datei1=\"$AUS\"" -e "PNG=\"$IN.png\"" ./zeichenhistogramm.gnuplot